C# 的 Dictionary
基本逻辑
C# 的 Dictionary 是一种常用的数据结构,支持泛型,避免了类型检查和装箱,在HashMap的基础上有性能上的提高,内部逻辑也有一些区别。插入查找和删除的渐进复杂度都是O(1)。
逻辑结构 上,Dictionary使用桶和链表存储,对于任何一个对象,调用其 GetHashCode() 将对象映射为一个整数,范围是整个 int,再去掉符号位取余,将其映射到对应序号的桶里存放。 当预设的容量不够时候,字典会自动进行扩容。
以容量为 7 的字典中一个字串“Apple”为例:
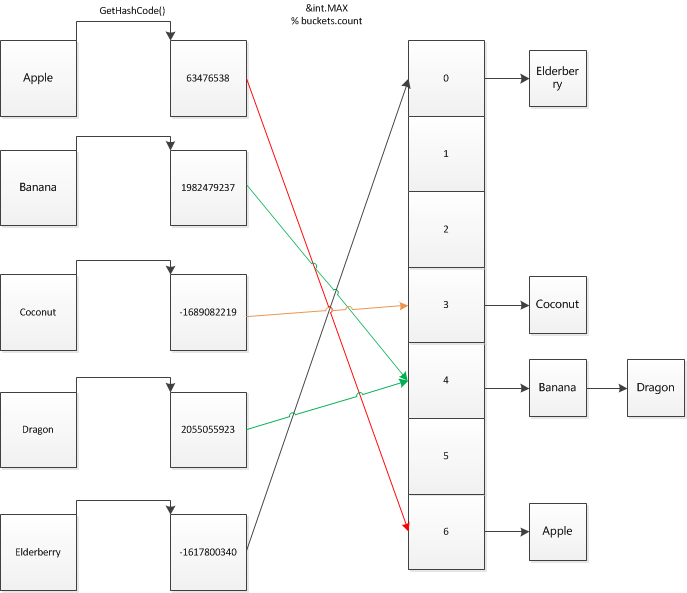
“Apple” 经过 string.GetHashCode() 求得hash值为 63476538 ,再去符号取余得6,于是被存到bucket的6号位,其他元素同理。
物理结构 上,右侧的桶和链表分别是两个数组buckets和items: items 是 Entry[] 类型,每个Entry都代表了链表的一个节点,有四个字段:key,value,hashCode,next buckets 是从 bucketIndex 到 entryIndex 的映射,保存了每个链表的头位置
bucketIndex = (hashCode & int.max) % buckets.count
entryIndex 基本逻辑是按照存放顺序,除非删除造成了空洞,空洞逻辑见下面
所以插入 “Apple” 之后,字典的物理结构如下:
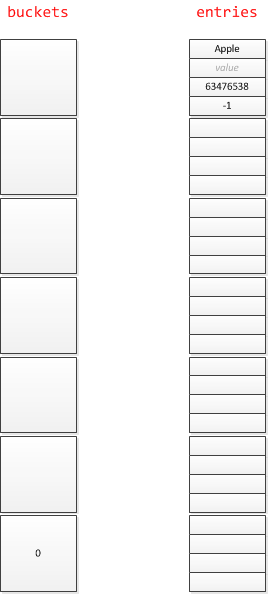
再依次插入 “Banana” 和 “Coconut”,很幸福没有碰撞:

插入 “Dragon” 的时候,hashCode 为4,和Banana出现了碰撞
先把Dragon放进 entries 3号位(entryIndex按插入顺序放),然后修改buckets[4] 指向Dragon,Dragon的next指向Banana:

删除 && 空洞
没有删除过元素的情况下,entries数组只要向下排就好了,有一个游标 count 指示当前可用的第一个节点,但是在删除过的情况下,entries会产生空洞需要回收。此时所有被使用过的空洞会串联成一个链表,由一个freeList:int变量指向其头节点

删除Banana之后
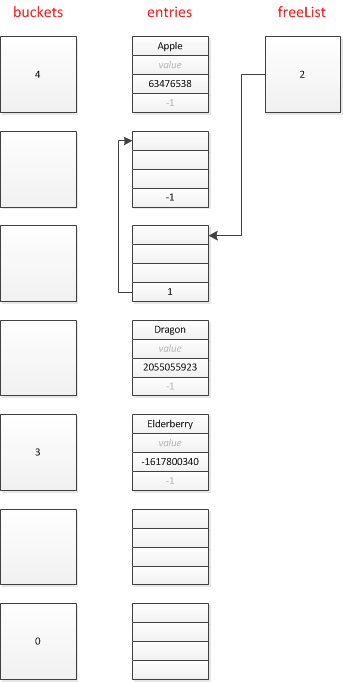
再删除Coconut之后
插入元素时,如果freeList有回收节点,优先使用,而不需要移动count游标。同样,每次也是从链表头开始优先使用。
扩容
插入元素时,如果发现freeList已经用尽,count也移动到了最后,也就是需要扩容了。出于某种神秘原因,buckets的长度(也就是entries的长度)必须为一个质数,这个质数的选择是通过 HashHelpers.GetPrime 方法精心选择的,不小于当前容量的2倍
扩容之后,buckets需要重排,因为buckets的索引是从Hash值去符号取余得到,而entries不需要重排,只是简单copy到新数组就行了
所以扩容的代价除了分配新内存之外,时间上是需要把bucket的索引全都重新算一遍
缩容?不存在的。
可能的性能问题
- 由于空间预留不准确造成频繁的扩容,以及扩容之后又大幅删减造成空间浪费
- 数组不超过 7199369 的时候,扩容所需的质数是查表得出,速度很快,超出之后,每次扩容都需要临时计算以找出下一个质数
- 数组使用 string 做为 key 的时候,计算其 hashCode 时需要遍历所有字符,时间复杂度是线性级别,如果 key 特别长而字典元素又比较多,每一次增删查都需要大量计算,此处时间消耗不容忽视。当采用其他引用类型作为key的时候,直接采用其地址作为Hash,所以速度反倒很快,哪怕是一个数组,或者超复杂的对象。